Hello Tensorflow
‘Big data’에 이어 ‘(Machine, Deep) Learning’ 라는 단어가 요즘에 엄청 뜨거운 것 같습니다. 얼마 전 Tensorflow-KR의 행사에 참가했었을때 사람들로 가득찬 구글 캠퍼스를 보고 머신러닝의 인기를 실감 할 수 있었습니다.( 8월에 곧 열릴 Pycon 세션 목록만 보더라도 머신러닝과 딥러닝 세션이 작년에 비해 엄청 많다는… ) 얼마 안되었습니다만, 저는 현재 혼자서 머신러닝을 공부하고 있습니다 (힘들어요 ㅜㅜ).

앞으로 제가 공부하면서 익힌것들을 정리도 하고 또 혹시나 다른 분들께 도움이 될 수 있을까 하는 생각에 머신러닝과 관련해서 포스팅을 시작하고자 합니다. 오늘은 머신러닝의 간략한 소개와 앞으로의 머신러닝, 딥러닝의 공부의 동반자가될 Tensorflow의 특징들을 정리 해보겠습니다. Tensorflow에 부분의 설명은 최근에 oreilly에 올라온 Hello Tensorflow 라는 글에서 참조하였습니다.
이 글에서는 Tensorflow의 특징을 살펴보고 이를 아주 심플한 뉴런을 텐서플로우로 구현해보면서 딥러닝의 맛을 봅니다.
-
머신러닝, 딥러닝
- 머신러닝, 딥러닝이란?
- data-driven approach, 머신러닝 왜지금 핫한가?
-
이름만 알아도 반은 안다.Tensor 와 Flow를 알아보자
- TensorFlow 특징(graph, Session)
- TensorBoard로 사용해보기
-
TensofFlow로 간단한 뉴런 만들어보기
- 코딩하는데, 생물시간도 아니고 왜 뉴런인가?
- 뉴런 학습시키기, forwardpropagation 과 backpropagation
본격적인 설명으로 들어가기전 머신러닝과 한 가지 Data-Driven Approach 컨셉부터 분명히 가지고가는게 좋을 것 같습니다. 예를들어 보겠습니다. 남자와 여자의 사진을 보고 성별을 구분하는 프로그램을 만들어라는 과제가 주어 졌다면, 어떤 생각이 드시나요? 남자는 머리가 짧으면 남자라고 정의할까요? 이렇게 되면 머리가 짧은 여자분은 또 머리가 긴 남자분의 사진이 주어지면 컴퓨터는 틀리게 되죠. 사과와 오렌지를 구분하는 과제였다면 빨간것은 사과라고 정의 할까요? 그러면 초록색 사과는 어떻게 될까요? 이렇게 현실적으로 남자와 여자의 특징, 사과와 오렌지의의 특정을 모두 정의하긴 너무나 어렵 너무나 많은 변수가 생깁니다.
이처럼 남자는 머리가 짧고, 키가 크며… 사과는 빨갛며…
if (hair < 15cm) and (tall > 180cm):
this is man
...
if color is red:
this is red
...
이런식으로 하나 하나 특징들에대한 미리 특정 요소들을 명시적으로 정해두고 프로그래밍하는 접근과 달리 data-driven approach는 컴퓨터에게 남자 사진을 수십만장을 보여주고 이는 남자다. 여자 사진을 수십만장을 보여주고 이것은 여자다 또는 사과와 오렌지 사진을 수십만장을 보여주고 이것은 사과다 이것은 오렌지다라고 학습을 시키는 접근 방법 (without being explicitly programmed)입니다. 새로운 사진이 주어졌을때 컴퓨터는 정확히 뭔지는 모르겠지만 이 사진은 이때까지 보여준 남자 사진과 비슷하군 이 사진은 남자야, 사과 사진과 비슷하군 이 사진은 사과야 하는 것입니다.
이때 컴퓨터가 처음 부터 능동적으로 배우지는 못하니 사람이 학습(learning) 알고리즘을 프로그래밍 해주고 이에 따라 컴퓨터는 양질의 데이터가 많이 들어 올 수록 점점 더 주어진 task를 잘 완수하는 기계(Machine)가 되어 갑니다. 이때 기계가 데이터를 학습하는 것을 말 그대로 머신러닝이라고 부릅니다.
머신러닝은 마치 사람이 나이가 들수록 경험이 쌓이면서 능력이 향상 되는것과 비슷합니다. 학습의 종류에는 수 많은 방법들이 있는데 그 중에서 사람의 신경망에서 힌트를 얻은 학습방법을 사용하는 머신러닝을 딥러닝(Deeplearning)이라고 부릅니다. 이제 저 같은 사람들은 이 학습 알고리즘들을 수학적, 통계적 접근방법 등 을 통해 공부하는 것이죠.
머신러닝의 정의: 즉, 어떠한 태스크(T)에 대해 꾸준한 경험(E)을 통하여 그 T에 대한 성능(P)를 높이는 것, 이것이 기계학습이라고 할 수 있다.[나무위키]
“A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E” __Tom M. Mitchell
여기서 두 가지를 생각해 볼 수 있습니다.
-
머신러닝으로 좋은 결과를 만들어내려면 데이터가 많이 필요하다.
-
이런 많은 데이터를 일정 시간안으로 빠르게 처리하려면 머신러닝을 할려면 고성능 컴퓨팅이 필요하다.
또 이를 보면 왜 지금 이토록 머신러닝, 빅데이터가 핫한지 알 수 있습니다.
-
첫째로 지금은 과거와 달리 디지털 환경의 보편화로 어마어마한 데이터가 쌓이고 있고
-
둘째로 고성능 컴퓨팅환경(cpu, gpu, cloud)을 비교적 저렴한 가격에 보다 쉽게 구축 할 수 있어서 경제성있는 컴퓨팅을 할 수 있게 되었습니다. 예를들어 컴퓨팅 스펙이 바쳐주지 않아서 학습을 하는데 1년정도 학습시간이 걸린다면… 안되겠죠.
이어서 바로 TensorFlow를 알아 보도록 하겠습니다.

많은 데이터를 다뤄야하니 많은데이터를 효과적으로 다룰 자료구조가 필요하겠죠? TensorFlow에서는 이를 위해 Tensor라고 부르는 자료구조를 씁니다. TensorFlow에서 Tensor는 다차원의 array, list라고 생각하시면 됩니다. 간단하게 말하자면 행렬이라고 생각하시면 될 것 같습니다(You can think of a TensorFlow tensor as an n-dimensional array or list).
# What is tensor?
tensor1 = 7 # 0-dimensional
tensor2 = [7] # 1-dimensional
tensor3 = [[1,2,3], # 2-dimensional
[4,5,6]] ...
...
TensorFlow라는 이름에 이제 flow가 남아있습니다. 눈치 채셨겠지만 TensorFlow는 이 Tensor의 흐름(Flow)을 요리조리 쉽고 멋지게 가지고 놀 수 있게해주는 라이브러리라고 생각하시면됩니다. 이제 TensorFlow의 로고가 다르게 보이실 겁니다. Flow 는 뒤에 graph에서 한 번 더 이야기 하겠습니다.
그렇다면 다차원 array인 Tensor들의 연산에 적합한 하드웨어는 무엇일까요? CPU 보다는 GPU(Graphics Processing Unit)가 더 적합하겠죠. 훨씬 빠르게 Tensor들의 연산을 실행 할 수 있습니다. 그래서 본격적으로 딥러닝을 시작하시게되면 필수적으로 GPU가 필요하실 것 입니다. 이외에도 최근에 구글은 머신러닝을 위해 만든 자체적으로 TPU(Tensor Processing Unit)라는 것을 만들어버렸습니다. 구글 검색, 구글 스트릿뷰 등 많은 영역에서 이미 사용되어왔고 최근에는 이세돌과 바둑을 둔 알파고도 이 TPU를 사용했었다고 합니다. 아래사진은 TPU 입니다.

왜 TensorFlow 인가?
-
구글이 만들었고 구글이 직접 자사 서비스를 위해 사용한다.
-
오픈소스를 공개되어있고 이를 또 오픈소스 언어인 Python을 통해서 사용 할 수 있다.
저 두 가지 이유로도 충분히 많은 장점들이 느껴집니다. TensorFlow는 구글 브레인팀이 만들었다고 합니다. Tensorflow는 deep learning 뿐만 아니라 다른 머신러닝 알고리즘에서도 충분히 활용 할 수 될 수 있도록 만들어졌고, 여러 머신러닝 알고리즘들을 Python을 통해서 쉽고(?) 빠르게 만들어보고 실행시켜 볼 수 있습니다.
Python과 Tensorflow를 이어주는 일종의 연결고리는 무엇일까요? Numpy 패키지입니다. Python을 사용하는 입장에서 Tensorflow를 어떻게 보면 DeepLearning과 MachineLearning에 특화된 Numpy의 확장판이라고 볼 수 도 있을 것 같습니다. Python을 이용해 scientific computing한다고 하면 바로 Numpy 패키지가 바로 생각나실 것 입니다.
Numpy는 TensorFlow뿐만아니라 데이터 과학 등 Python의 scientific computing의 기본이 되고 일종의 인터페이스 역할을 하는 패키지이기 때문에 공부하시면 좋을 것 같습니다. Numpy와 관련해서 이번 TensorFlowKR에서 아주 하성주님께서 멋진 발표를 해주셨습니다. 한 번 보시길 강추!드립니다.
- Zen of Numpy, 하성주
-
아래 슬라이드는 이번 GDG Global Summit 2016에서 Introduction to TensorFlow 세션에 나온 구글의 딥러닝 사용량 증가를 보여주는 슬라이드입니다. 링크를 걸어두었으니 딥러닝, 머신러닝이 처음이신분은 보시길 추천드립니다. ^^; 또한 세션 발표자는 Youtube에 Machine Learning Recipes 시리즈를 업로드 하고있습니다. 이 또한 보시길 추천 드립니다.
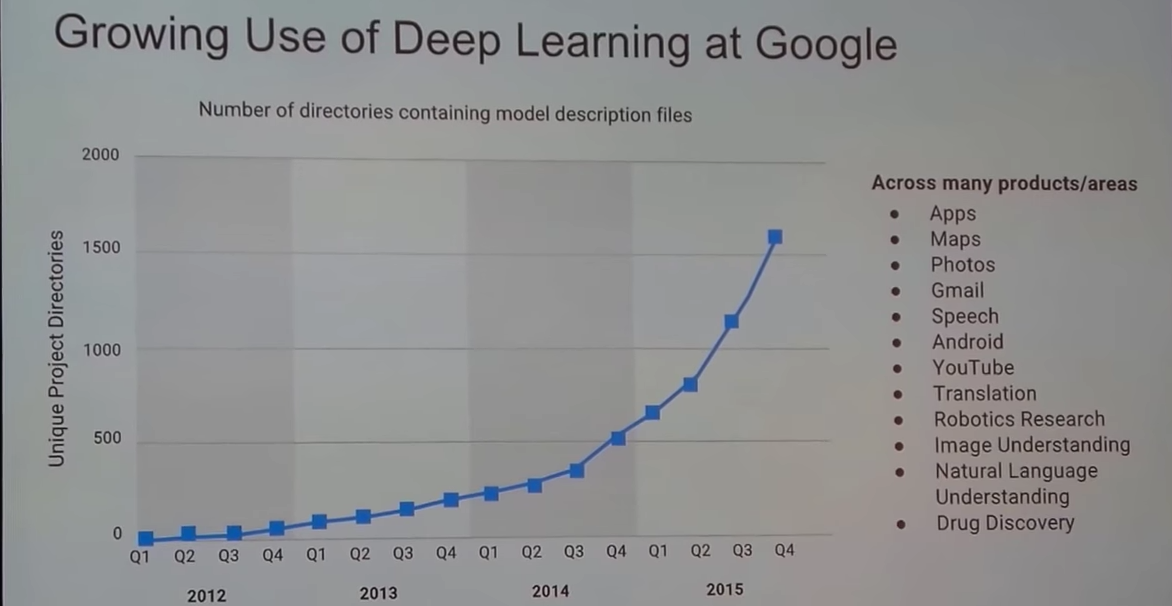
자 이제 본격적으로 TensorFlow에 들어가보겠습니다.
- Graph, node, edge
-
Session
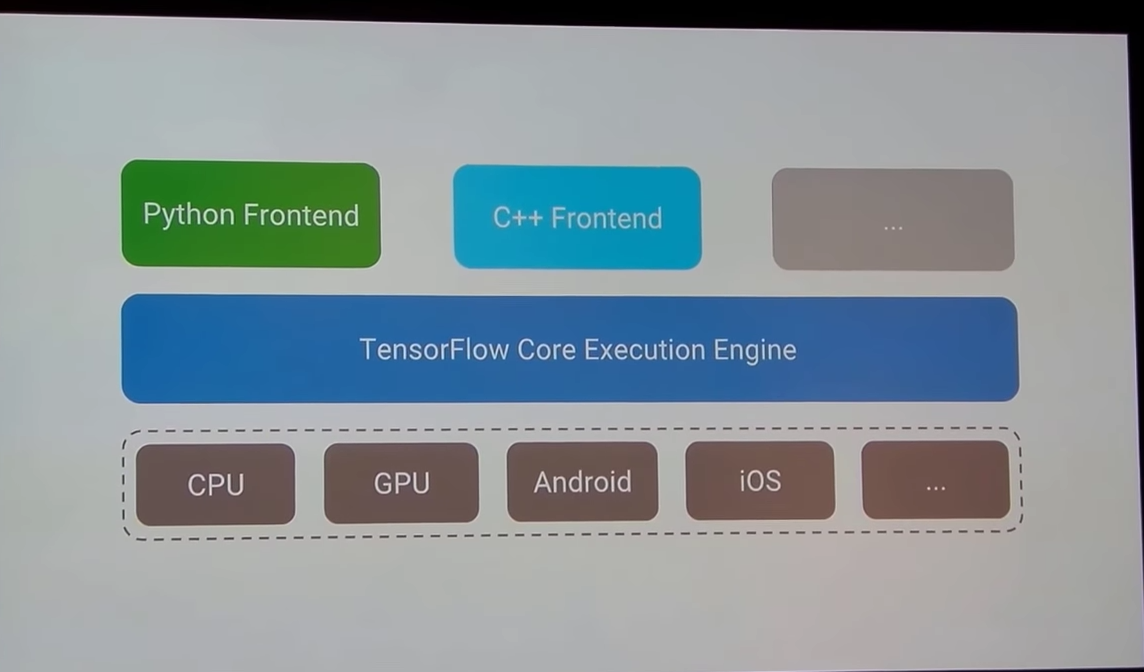
위 슬라이드는 Tensorflow의 큰 구조를 보여주고 있습니다. 보시면 Python이 TensorFlow Core을 사용할 수있게 해주는 API역할을 하고 있습니다.
왜 이럴까요? Deep Learning의 Deep이 괜히 Deep 이 아니겠죠? (deep —> 복잡하다) 복잡하고 많은 처리가 필요한 Deep learning에서 단순히 script언어인 Python만으로 해결되긴 어려울 것입니다. 그래서 여러 Task들을 Python으로 코딩해놓으면 Tensorflow가 내부적으로 다른 언어로 바꾸어 실행하기도하고 또 이를 필요에따라 여러 CPU 또는 GPU에서 실행이 되어야 할 때가 있는데 이 과정도 Tensorflow가 쉽게 처리하도록 해줍니다.(Python으로 잘 추상화 되어있다)
-
딥러닝을 하기 위해서 해결해야할 task들을 수 많은 변수들과 연산들을 이용해서 코딩해야하고
-
많은 computiation들을 빠르게 처리하기 위해서 여러 task들을 Python으로 코딩한 코드들을 Python 이외의 언어로 바꿔서 실행 해야하며
-
이를 여러 device(cpu, gpu…) 에서 실행이 해야하며, 분산환경에서 나온 결과를 다시 합치고 나누고하는 등의 복잡한 처리가 필요한 경우가 많이 생길 것 입니다.
정리하면 위와 같은 경우를 Tensorflow 를 이용해서 처리해나가는 것입니다. 이런 맥락에서 보면 Python 에서 Tensorflow 라이브러리를 써서 짜는 코드들은 TensorFlow의 Core Execution Engine을 어떻게 사용할 것이라는 계획서를 Python으로 적어내는 것과 비슷합니다.
그렇다면 이런 상황과 프로세스에 적합한 프로그래밍 하기 위해 보통 프로그래밍 방식과는 조금 다른 부분이 필요하게 됩니다. 여기에서 TensorFlow의 특징이자 저 같은 초보자들이 햇갈려하는 포인트가 나오는데요, 바로 코딩하는 부분과 실행 단이 독립적으로 분리되어 있습니다. 바로바로 실행이 되는 Python과 달리 tensorflow에서 코드들은 Session이라는 환경 아래에서만 실행됩니다.
위에서 언급한 Tensorflow를 어떻게 어떻게 쓰겠다라는 계획서를 Python으로 짜기 위해서 Tensorflow에서는 Graph라는 것을 사용합니다. 계획서에 담겨있는 여러 계획(작동)들을 operation이라고 하고 이 계획서를 graph라고 볼 수 있습니다.
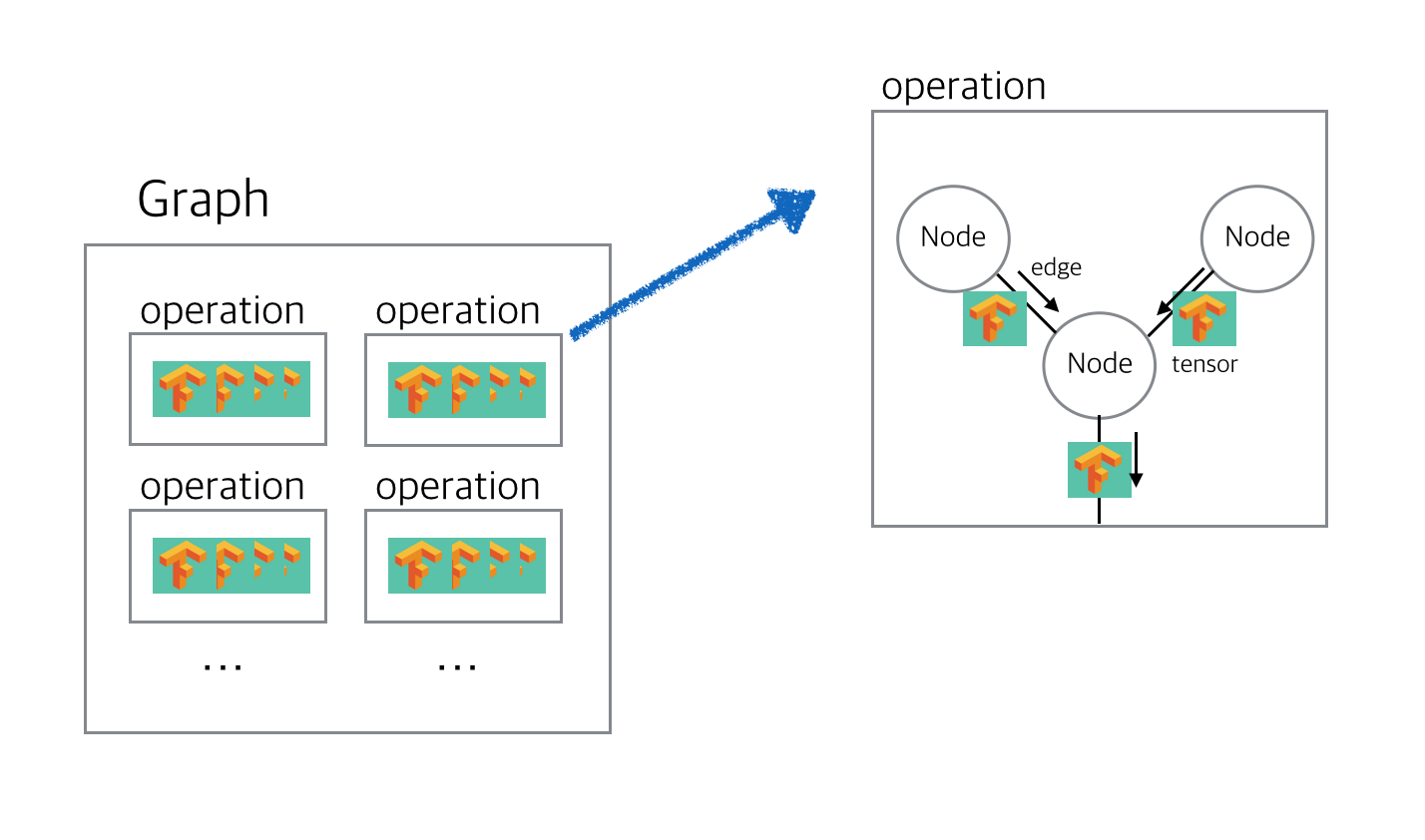
조금 더 상세히 들여다 보면 이 operation이 정의된 부분을 node라고 부르고 node와 node사이를 이어진 부분을 edge, 그리고 node와 node사이의 이 edge로 데이터들, 처음에 말한 다차원 배열인 Tensor들이 왔다 갔다 하게 됩니다. 이 operation이 다 담겨져있는 object를 graph라고 부르는 것입니다.
graph는 Tensor들을 어떻게 연산할 것인지 방법을 적은 종이가 빼곡히 들어있는 주머니와 같다고 할까요.(마치 앞에서 여러 데이터들을 Tensor로 담았던 것 처럼 이 여러 연산들을 graph라는 주머니에 담아버렸다고 저는 이해하고있습니다.) 이 graph들을 만드는 것을 위해서 말한 TensorFlow의 Flow라고 볼 수 있습니다. 마지막으로 이 graph 속 operations들은 Session이라는 공간 아래에서 한 번에 실행 됩니다.
이처럼 우리가 해야할 task들을 operation 덩어리들(graph)로 적어주면 나중에 tensorflow가 이 operations 들을 다른 언어로 바꾸거나 다른 device에서 실행하는 등의 여러 복잡한 처리들을 실행하고 관리하는데 훨씬 편리할 것 입니다.
건물을 짓는다면 Tensor는 건축재료, graph는 설계도, Session 은 건물이 지어지고있는 공사현장과 같다고 할 수 있습니다.

이 부분을 코드로 다시 살펴보겠습니다.
graph = []
operation1 = [ 'a = 1']
operation1
# ['a = 1']
operation2 = [ 'b = 2']
operation3 = [ ‘c = a + b’]
graph.append(operation1)
graph
# [['a = 1']]
graph.append(operation2)
graph
# [['a = 1'], ['b = 2']]
Python은 위 처럼 operation들이 바로바로 실행이 된다고 하면 tensorflow을 사용한 코드들은 이렇게 바로바로 작동하지 않습니다. Session아래에서 실행이 됩니다.
따라서, 위처럼 python에서 operation1 = [‘a=1’] 라고 선언을 하면 operation1이라는 변수는 직접적으로 [‘a=1’]이라는 object를 직접적으로 가리키고 있지만 tensorflow에서 이와 같은 선언은 바로 graph에 들어가는 operation을 작성하는 것입니다.
a = 1
이 코드를 python에서 ‘a라는 변수는 1로 지정’라고 말을 표현을 한다면, Tensorflow 스타일은 ‘a 변수를 1로 지정 할꺼야’에 가까운 것이죠.
Tensorflow는 어떨까요
import tensorflow as tf
이렇게 tensorflow를 import 하면 이미 벌써 내부에 _default_graph_stack에 default Graph가 생기는데요, graph에 tf.get_default_graph() 명렁어로 쉽게 접근 할 수 있습니다.
graph = tf.get_default_graph()
그러면 이 graph에 operation들이 차차 담기게 되겠죠. 현재는 비어있는 것을 볼 수 있습니다.
graph.get_operations()
# []
그렇다면 상수를 하나 선언하고 operation을 살펴보겠습니다.
input = tf.constant(1.0)
operations = graph.get_operations()
operations
# [<tensorflow.python.framework.ops.Operation at 0x117a440f0>]
바로 볼 수는 없지만 operations에는 operation이 리스트 형태로 들어있다는 것을 알 수 있습니다. 또 operation 안에는 해당 operation에서 사용할 node가 들어있겠죠. 그러면 이 부분도 확인 해보겠습니다.
operations[0].node_def
# name: "Const"
# op: "Const"
# attr {
# key: "dtype"
# value {
# type: DT_FLOAT
# }
# }
# attr {
# key: "value"
# value {
# tensor {
# dtype: DT_FLOAT
# tensor_shape {
# }
# float_val: 1.0
# }
# }
# }
무슨 JSON 비슷한게 적혀져 나오는데 name: “Const”라고 적혀있고, float_val: 1.0을 적혀있는 것보니 아까 선언한 input을 말하고 있는 것 같습니다. 이것이 바로 나중에 Session 아래에서 실행될때 tensorflow가 보고 실행할 부분이자 graph라는 계획서에 담겨있는 계획들 입니다.
이 JSON과 비슷하게 생긴것은 Protocol buffer(구글이 버전의 JSON?)라고 합니다. Tensorflow는 내부적으로 이 Protocol buffer을 사용합니다.
자 이제 input을 출력해보겠습니다.(Session 아래에서만 실행됩니다)
input
# <tf.Tensor 'Const:0' shape=() dtype=float32>
sess = tf.Session()
sess.run(input)
# 1.0
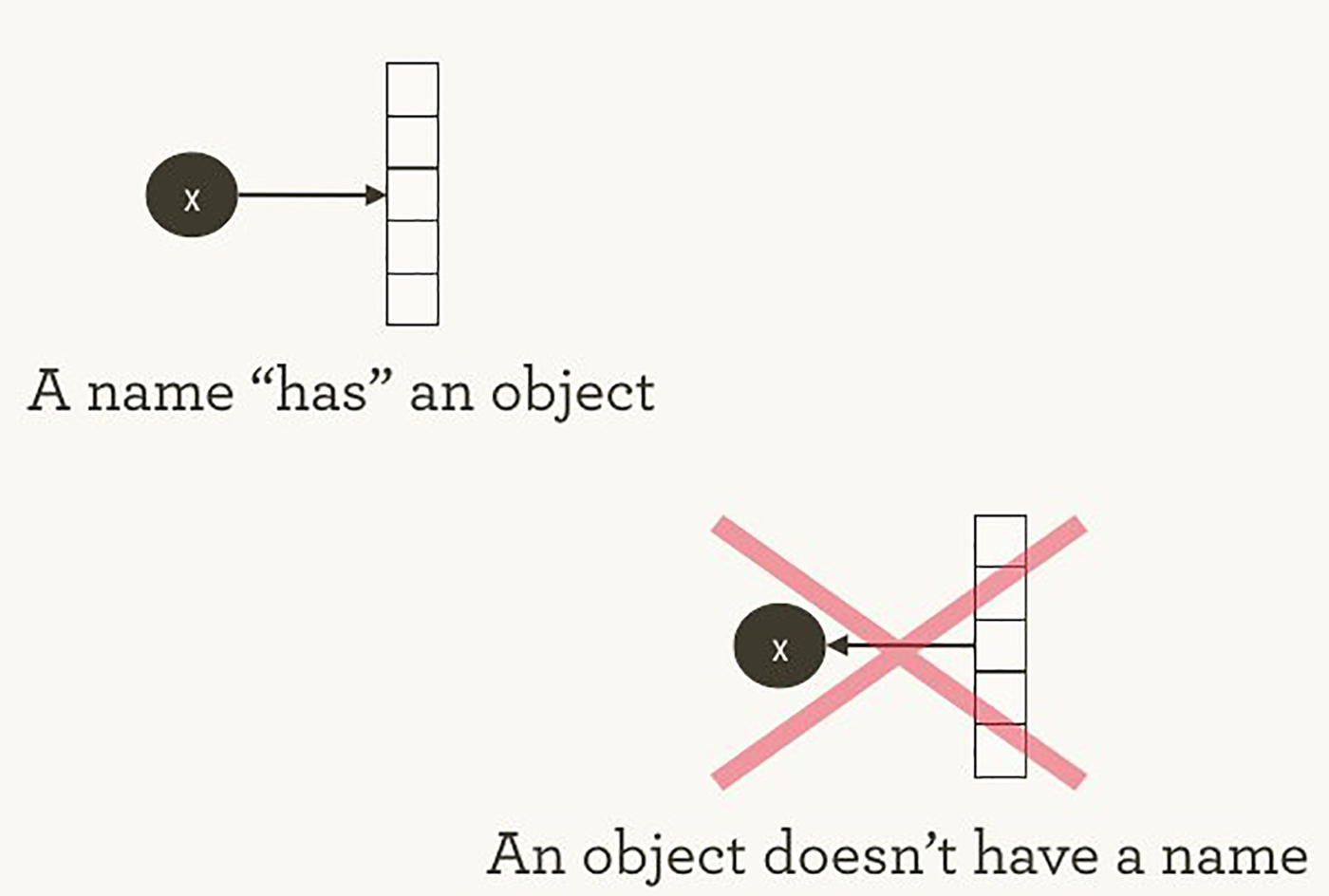
단순 python 의 출력 코드가아니라 tensorflow의 graph가 실행 된 것 입니다. R계의 초고수 Hadley Wickham의 설명을 인용 해보겠습니다. Names “have” objects, rather than the reverse. 아래 그림이 조금 이해가 되시나요? Tensorflow를 사용하실 수록 점점 이 그림에대한 이해도가 높아지실 것 입니다.
## ‘초간단’ Tensorflow 뉴런 만들어보기
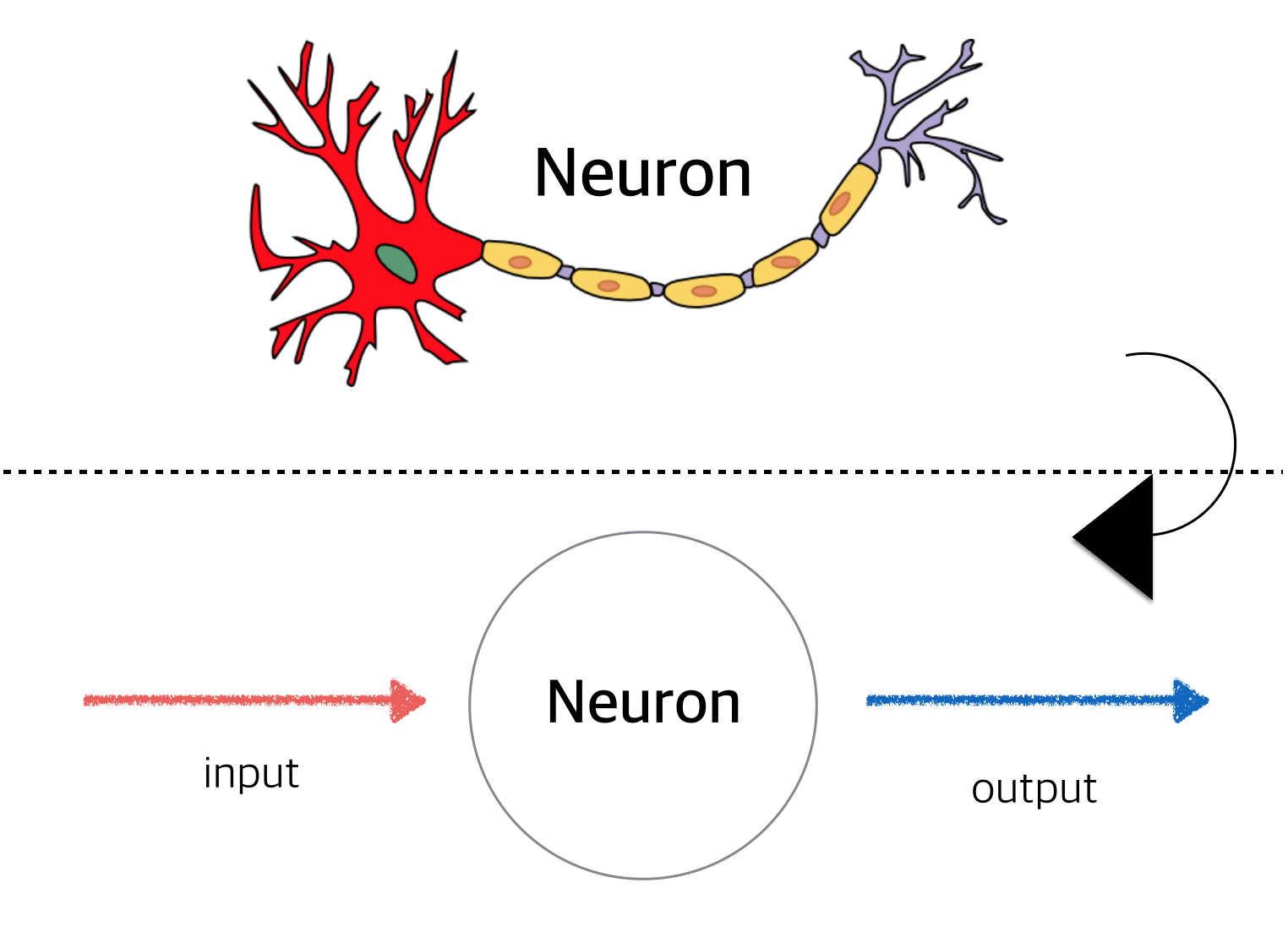
이제 Tensorflow으로 간단한 뉴런을 만들어 보겠습니다. 일단 잠깐 뉴런에대해서 살펴보겠습니다. 생물시간도 아니고 코딩하는데 뭐 계속 뉴런, 뉴런 할까요? 바로 뉴런을 단순하게 보면 하나의 함수 형태로 볼 수 있기 때문입니다. 처음에 설명한 머신러닝을 보면 결국 머신러닝은 데이터를 입력받아 학습해서 원하는 출력값을 만들어내는 함수로 볼 수 있는데요. 뉴런의 매카니즘을 가만히 살펴보니 단순화 시키면 일종의 input을 받아서 output을 출력하는 함수(Function)로 볼 수 있다는 것입니다. 그런데 실제 머신러닝에서 필요한 입력과 함수가 한두개의 일까요?
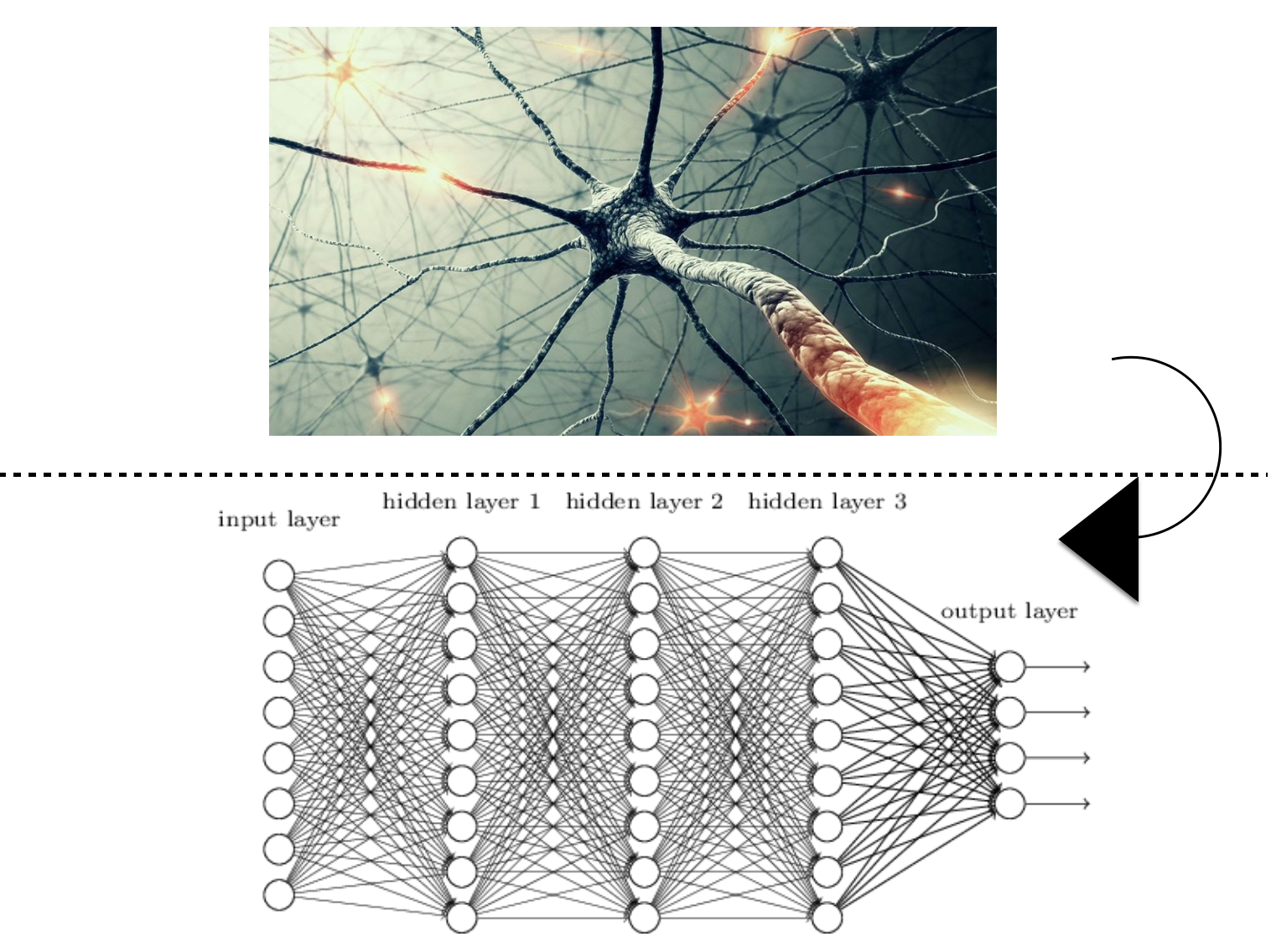
아닙니다. 수많은 입력값들을 수많은 함수들을 통해서 처리해야하는데요, 뉴런이 함수와 비슷하니 이 함수들을 우리 몸의 신경망처럼 들을 복잡하게 연결시켜놓으면 어떨까? 하고 만들어낸 머신러닝이 바로 딥러닝입니다.
그러나 여기서 tensorflow 코드로 만들어볼 뉴런은 bias도 activation function도 하나 없는, 입력이 하나 출력이 하나인 초간단 tensoflow 뉴런입니다.
학습을 해나간다는 것은 무엇이 계속 변해간다는 것이겠죠? 이 변하는 부분을 담당할 부분을 weight라고 합니다. 계속 변하는 값이므로 tf.constant로 선언한것과달리 tf.Variable 을 사용합니다.
weight = tf.Variable(0.8)
한 번 더 graph에 어떤식으로 operation들이 담겨있는지 확인해보겠습니다.
for operation in graph.get_operations():
print(op.name)
# Const
# Variable/initial_value
# Variable
# Variable/Assign
# Variable/read
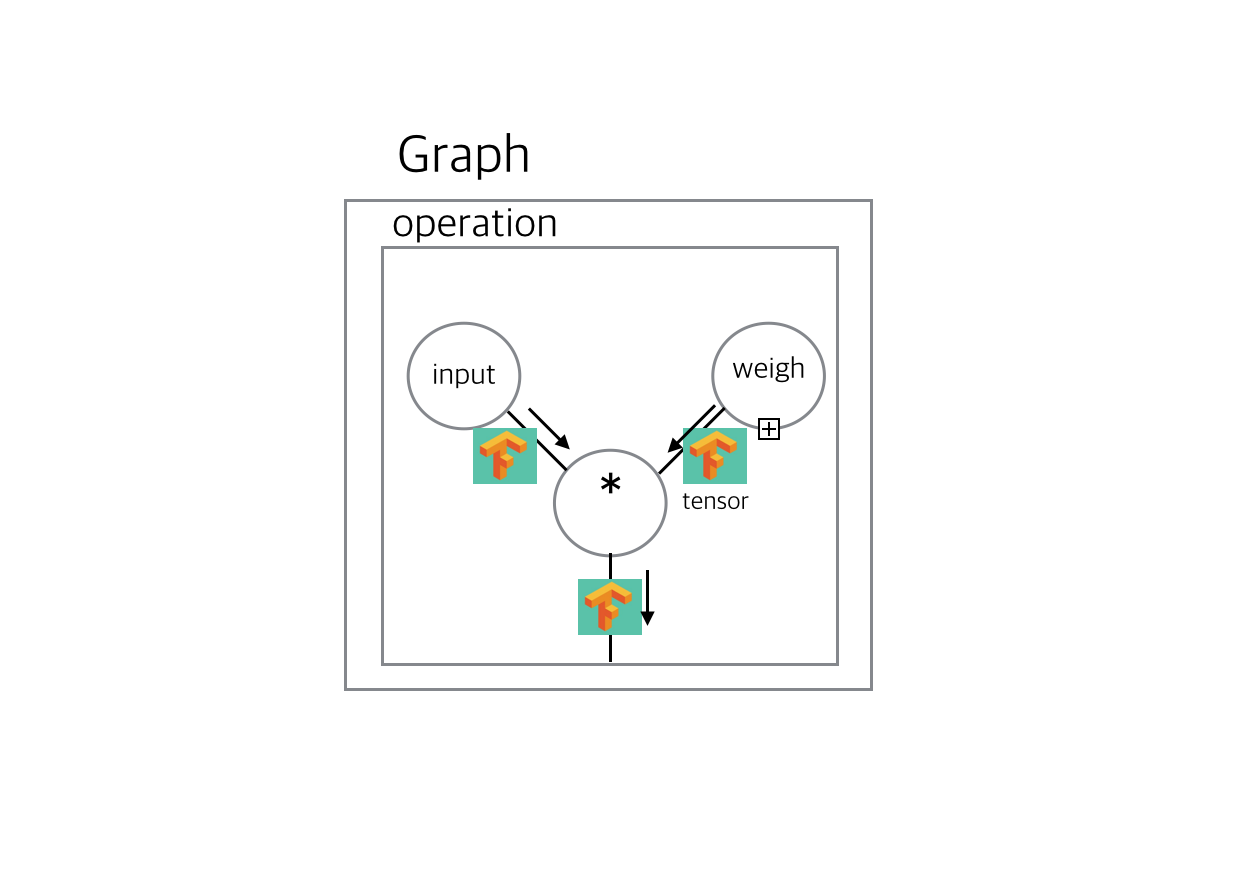
아까 input을 만드는 Const를 빼면 weight을 선언함으로써 4개의 operation들이 생겼습니다. Python 과 Tensorflow의 차이가 이제 확연이 느껴지실 것 입니다. 조금 더 직관적으로 이해하기위해서 연산을 해서 안에 operation을 살펴보겠습니다. 뉴런이 출력할 output 입니다.
output = weight * input
자 이제 graph에는 총 6개의 operation들이 들어 있을 것입니다. 그 중에 마지막은 weight * input 을 나타내는 곱하기 operation일 것입니다.
last_operation = graph.get_operations()[-1]
last_operation.name
# 'mul'
for op_input in last_operation.inputs: print(op_input)
# Tensor("Variable/read:0", shape=(), dtype=float32)
# Tensor("Const:0", shape = (), dtype=float32)
그림으로 보면 이렇겠죠.
주의 해야 할 것이 하나 더 있습니다. tensorflow에서 tf.Variable 같은 값이 변할 수 있는 변수를 선언을 하면 항상 Session 시작전에 graph에 들어있는 모든 변수들을 초기화해줘야 한다는 것입니다. 실제로 tf.Variable()로 선언을 했던 weight초기화전에 값을 보면 0.800000011920929로 0.8 과 달리 차이가 조금 나 있습니다.
name: "Variable/initial_value"
op: "Const"
attr {
key: "dtype"
value {
type: DT_FLOAT
}
}
attr {
key: "value"
value: {
tensor {
dtype: DT_FLOAT
tensor_shape {
}
float_val: 0.800000011920929
}
}
}
초기화를 하고 Session에서 출력해보겠습니다.
init = tf.initialize_all_variables()
sess.run(init)
see.run(output_value)
# 0.80000001
훨씬 0.8에 가까워 졌다는 것을 볼 수 있습니다.(딱 정확히 0.8은 아니지만 32-bit float에서 최대한 0.8에 가까운 값입니다.) 반드시 초기화 해줘야합니다. 안 하고 싶다고해도 초기화 하지 않고 실행한다면 FailedPreconditionError을 출력해서 실행이 되지 않습니다.
자 이렇게 벌써 인공뉴런을 만들어 보신 것입니다. 지금은 input , output이 몇 개 안되지만 신경망처럼 수많은 인풋과 아웃풋이 필요한경우 알아 보기 힘들것입니다. 가뜩이나 Session아래에서 실행되는 탓에 바로바로 확인하기 힘든데요. 그래서 Tensorflow에서는 이를 위해 graph를 시각화해주는 Tensorboard라는 것을 제공해 줍니다. 아래처럼 Tensor들이 어디로 어떻게 들어와서 나가는지 쉽게 볼 수 있습니다.

텐서보드를 활용해 저희가 만든 뉴런도 시각화 해보겠습니다.
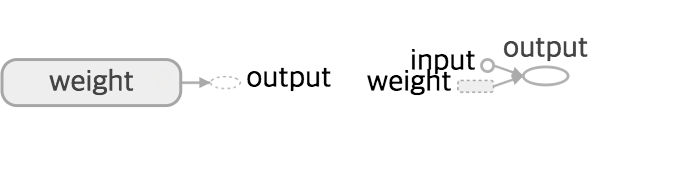
현재 뉴런을 Tensorboard를 이용해서 시각화해보면 위와 같은 모습입니다. Tensorboard에서는 시각화 결과물을 보고 훨씬 더 알아 보기 쉽도록 이름을 설정해줘야 하는데요. 나중에 TensorBoard에서도 보기편하도록 다시 input, weight, output을 설정해보겠습니다.(여기서 이름을 정해주는게 원래 Python에서 변수이름을 정해 주는 것과 비슷하다고 볼 수 있습니다.)
x = tf.constant(1.0, name='input')
w = tf.Variable(0.8, name='weight')
y = tf.mul(w, x, name = 'output')
이름을 지었으니 이제 TensorBoard를 위한 파일을 만들어야 하는데요. 이를 위해 Tensorflow의 SummaryWriter라는 것이 필요합니다. 혹시 Python으로 csv를 다뤄보셨으면 csv.writer()와 비슷하게 생각하시면 될 것 같습니다.
summary_writer = tf.train.SummaryWriter('log_simple_graph', sess.graph)
SummaryWriter 첫번째 인자에는 파일이 담겨질 폴더명이 두번째인자에는 graph가 오게 됩니다. 해당 폴더가 없으면 넘어온 인자값으로 폴더가 새로 생깁니다. 이제 log_simple_graph라는 폴더에 저희 sess에 있는 graph를 기록했습니다. TensorBoard를 실행시키시고 싶으시면 이제 커맨드라인으로 가셔서
$ tensorboard --logdir=log_simple_graph
위 명령어를 치시고 브라우저에서 localhost:6006/#graphs 로 들어가 보시면 시각화 된 것을 보실 수 있습니다.
### 이제 머신러닝, 딥러닝에서 말하는 러닝을 해보도록 하겠습니다.
뉴런은 입력된 input x에 weight w 를 곱해서 y라는 ouput을 만들어내는 뉴런입니다. 이때 뉴런이 맞춰야할 값을 target라고 하고 값은 0 이라고 가정하겠습니다(1로 설정 할 수도, 100으로 설정할 수도 있습니다…). target이 0 이니 최종적으로 학습이 잘 끝나면 이 뉴런은 입력값이 1일때 0을 만들어내는 뉴런이 되어야 합니다. 현재는 0.8 * 1 = 0.8 으로 0.8을 출력하는 뉴런입니다.
그렇다면 이 뉴런이 잘 하고있다, 즉 뉴런의 성능을 측정하러면 어떤 값을 사용해야 할까요? 정답인 target 0과 현재 출력값 0.8의 차이가 작아질 수록 뉴런이 제 역할을 다 하고 있다고 볼 수 있습니다. 그래서 이 차이인 ouput - target(0.8 - 0 = 0 )을 하나의 지표로 사용하고 머신러닝에서는 loss 또는 cost 함수라고 합니다. 실제로는 제곱을 해주어 output - target 이 loss로 쓰입니다.
구체적으로 학습은 무엇을 의미할까요? 현재 뉴런을 살펴보면 w*x = y, 들어온 input x에 weight w를 곱해주는게 뉴런의 역할입니다. 여기에서 뉴런이 조절할 수 있는 값은 weight 밖에 없습니다. 이 뉴런이 출력하는 output을 우리가 원하는 정답인 target 값에 가능한한 가깝게 weight값을 바꿔나가는 과정이 러닝에 해당합니다. 즉 다시 말하면 뉴런을 위에서 말한 loss를 최소화 시키는 뉴런으로 최적화 시키는 과정이 러닝에 해당하는 것입니다. 또한 이 과정을 학습한다 또는 트레이닝 시킨다고도 하는데, 이 학습시키는데 사용한 데이터를 학습데이터 train_data 라고 부릅니다. 여기에서는 input 1과 정답에해당하는 target 0이 학습데이터가 되겟습니다.
target = tf.constant(0.0)
loss = (y - target)**2
이어지는 질문으로 그러면 어떻게 loss를 최소화하는 weight으로 바꾸는지, 즉 뉴런을 어떻게 최적화하는가?가 궁금하실 것입니다. 여기서 보통 GradientDescent라는 방법이 사용됩니다.(여기에서 GradientDescent를 다루지는 않겠습니다.) 물론 tensorflow에서는 이부분을 하드코딩할 필요없이 한 줄이면 됩니다.
optim = tf.train.GradientDescentOptimizer(learning_rate = 0.025)
위의 learning_rate를 간략히 설명을 드리자면 얼마나 빠르게(많이) weight을 변화시킬것인가, 얼마나 빠르게 뉴런을 최적화 시킬것인가 하는 속도를 조절하는 값입니다. 무조건 빠르면 좋을 것 같지만 이 learning_rate값이 너무 빨라버리면 탈이 납니다. 그래서 너무 크지 않도록 적정한 값을 잘 설정해줘야합니다. 여기선 0.025로 설정했습니다.
grads_and_vars = optim.compute_gradients(loss)
sess.run(tf.initialize_all_variables())
sess.run(grads_and_vars[1][0])
# 1.6
자 위는 Gradient 값을 출력한 것입니다.(loss를 weight으로 미분한 값) 식으로 보면 2*0.8 = 1.6 입니다. 뉴런은 weight는 이 Gradient 값 1.6에다가 learning_rate를 곱한 1.6 * 0.025 = 0.04 만큼 변하게 됩니다(작아집니다). weight을 변화(최적화)시켜 보겠습니다.
sess.run(optim.apply_gradients(grads_and_vars))
sess.run(w)
# 0.75999999 #about 0.76
참고로 이 과정을 loss를 다시 뒤로 전파한다고 해서 backpropagation이라고 합니다. 반대로 처음 부터 계산해나간 과정을 forwardpropagation이라고 합니다.
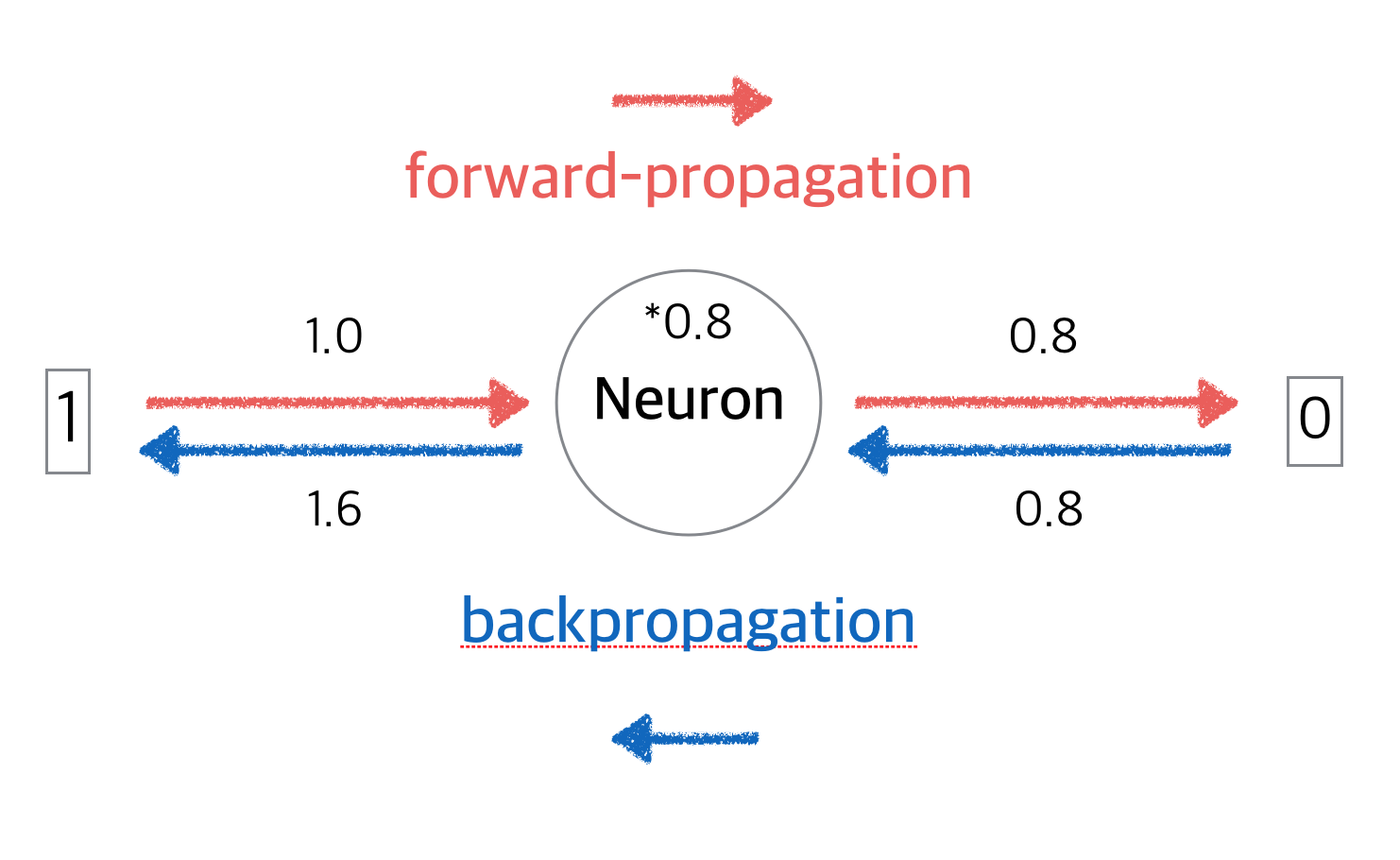
머신러닝의 학습은 이 앞으로 왔다 뒤로 갔다가 하는 forwardpropagation 과 backpropagation의 반복이라고 할 수있습니다. 아까 저희는 한 번 왔다갔다 한 것이지 학습이 끝난것은 아닙니다. 아직 출력값이 0이 되려면 한 참 멀었습니다.그렇다면 방금 한 과정을 계속해서 반복해야 할텐데 아까 처럼 힘들게 반복할 필요는 없습니다. 위 training 과정을 100번 하고 싶다면 아래와같이 코딩하면 됩니다.
train_step = tf.train.GradientDescentOptimizer(0.025).minimize(loss)
for i in range(100):
sess.run(train_step)
#
sees.run(y)
# 0.0044996012
output y 까지 출력해 보았습니다. 자 output이 이제 원하는 0에 가까워 진것을 확인 할 수 있습니다.
학습과정 , TensorBoard로 보기
아까 위처럼 트레이닝을 할때 잘되고있는지, 우리가 원하는 값을 출력하도록 뉴런이 잘 변하고있는지 확인을 하면서 작업을 해야하는데요. 예를들어 트레이닝과정에서 출력값을 확인 할 수 있는데요. 확인 하려면 아래와 같이 하면 됩니다.
sess.run(tf.initialize_all_variables())
for i in range(100):
print("학습 횟수 {}, 출력값: {}".format(i, sess.run(y)))
sess.run(train_step)
#
# 학습 횟수 0, 출력값: 0.800000011920929
# 학습 횟수 1, 출력값: 0.759999990463
# ...
# ...
# 학습 횟수 98, 출력값: 0.00524811353534
# 학습 횟수 99, 출력값: 0.00498570781201
자 그런데 이렇게 하면 직관적이지 않으니 여기서 TensorBoard를 활용해서 위 결과를 그래프로 보면 훨씬 효과적일 것입니다.
summary_y = tf.scalar_summary('output', y)
summary_writer = tf.train.SummaryWriter('log_simple_stat')
for i in range(100):
summary_str = sess.run(summary_y)
summary_writer.add_summary(summary_str, i)
sess.run(train_step)
설명을 드리자면 , 우리가 확인하고 싶은 값 y를 계산하는 operation을 summary_y에 담아서 트레이닝 한 번 할때마다 tensorflow의 SummaryWriter를 통해 log_simple_stat이라는 디렉토리 안에 쓴다고 이해하시면 될 것 같습니다. Session 에서 summary_y가 실행되면 위에서 말한 tensorflow에서 사용하는 protocol buffer string 형태가 return 되서 summary_str에 저장이 될 것입니다.
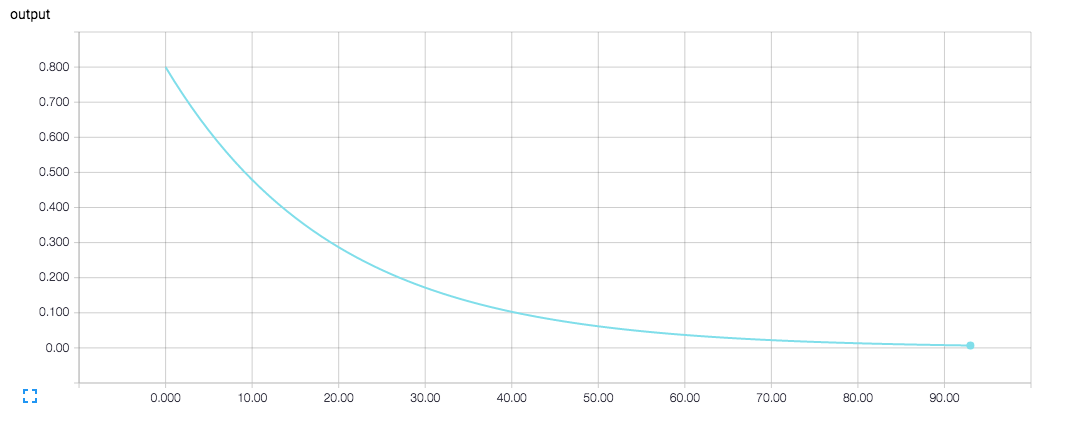
출력값 y 를 TensorBoard로 시각화한 결과 입니다.
최종 소스 입니다.
import tensorflow as tf
x = tf.constant(1.0, name='input')
w = tf.Variable(0.8, name='weight')
y = tf.mul(w, x, name='output')
y_ = tf.constant(0.0, name='correct_value')
loss = tf.pow(y - y_, 2, name='loss')
train_step = tf.train.GradientDescentOptimizer(0.025).minimize(loss)
for value in [x, w, y, y_, loss]:
tf.scalar_summary(value.op.name, value)
summaries = tf.merge_all_summaries()
sess = tf.Session()
summary_writer = tf.train.SummaryWriter('log_simple_stats', sess.graph)
sess.run(tf.initialize_all_variables())
for i in range(100):
summary_writer.add_summary(sess.run(summaries), i)
sess.run(train_step)
이후에는 무엇을 공부하게 될까요? 아래 질문들 처럼 위에서 해온 작업들을 뉴런 한 개가아니라 수 많은 뉴런들을 연결 시켜서 학습을 시키고 최적화 시키게 됩니다.
-
지금 뉴런하나지만 뉴런을 수십만개를 연결한 어떤 모양의 망(net)으로 만들어서 해볼까?
-
여기선 처음에 weight을 0.8로 시작을 했지만, 이 weight을 초기값을 어떻게 잘 설정 할 순 없을까?
-
지금 뉴런은 단순 한 *만 했지만, +, * 등의 복합적인 연산을 하는 뉴런이면 어떻게 될까?
-
복잡하게 연결된 Deep network에서 어떻게 하면 원하는 정답과 내 인공신경망의 출력값의 차이를[loss(cost)]를 잘 측정하고, forwardpropagation 과 backpropagation을 잘 할 수 있을까?
- ,,,
- ,,,
최대한 쉽게 써보려고 노력은 했는데 어떨지는 잘 모르겠습니다 ^^; 제가 설명을 잘 못한 부분이 있을 수도 있습니다. 혹시 오류나 지적할 부분이 있으시면 댓글로 알려주시면 감사하겠습니다 ! 그리고 혹시나 이 까지 다 해보시고 흥미를 가지셨다면 페이스북 그룹 TensorFlowKR을 운영하고 계시는 홍콩과기대 김성훈 교수님의 모두를 위한 머신러닝/딥러닝 강의를 보시길 추천드립니다!
처음 부터 많은 수식과 이론에… 자칫하면 학습의욕을 떨어질수도 있는데요 수학이나 컴퓨터 공학적인 지식이 없이도 쉽게 볼수 있도록 만드셨습니다. 저 또한 많이 배웠고 너무 감사드린다고 말씀드리고 싶습니다. 다음으로 머신러닝의 전반을 다루는 너무나 유명한 바이두의 Andrew Ng님의 머신러닝 강의, 비전쪽을 다루는 스탠포드 대학교의 cs231n, NLP를 다루는 cs224d강의 마지막으로 또 하나의 강의를 추천 드린다면 MIT Patrick Henry Winston 교수님의 Artificial Intelligence 강의 입니다. 설명이 간결하고 쉽게 가르쳐 주십니다. 아래에 링크를 적어두겠습니다.
-
CS231n: Convolutional Neural Networks for Visual Recognition
-
끝으로 읽어주셔서 정말 감사드립니다.
p.s) 올해 9월부터 대구 경북대학교 근처에서 머신러닝, 딥러닝과 관련해서 스터디 모임을 만들어보고자 합니다. 장소는 후원을 받기로 확정이 되었습니다. 같이 으쌰으쌰해서 열심히 공부해보실분 뿐만 아니라 이미 어느정도 실력으로 쌓고 넓은 아량으로 도움 주실분도 환영입니다. 페이스북 메세지로 연락을 주시면 감사하겠습니다 !! ^^;;